
How to use Debezium and Redpanda for change data capture
Leveraging Redpanda's compatibility with Debezium to stream changes from MySQL


This article was written by Redpanda Community member Almas Maksotov.
Introduction: how to set up CDC stream in Redpanda
In this tutorial, you are going to build a CDC stream using Redpanda and Debezium. Note that the entire Kafka Connect ecosystem works out of the box with Redpanda, as Redpanda is API-compatible with Apache KafkaⓇ.
What is change data capture (CDC)?
CDC is the process of recognizing when data has been changed in a source system so a downstream process or system can take action on that change.
Why would you use it?
Here are some popular use cases:
- Safe migration from legacy systems
- Division of monolithic data
- Real-time analytics
- Easy integrations
- Cache invalidations
- Outbox patterns
Useful links about technologies used in this tutorial
Note: Redpanda aims to be fully compatible with Kafka APIs, so all existing connectors should work with Redpanda without any changes.
Prerequisites
Quick tour of services
- Redpanda - The modern data streaming platform
- Kafka Connect - Integrations that connect Kafka with other data systems
- Debezium - A set of plugins used by Kafka Connect to capture changes in databases
- MySQL - Database
Debezium and Redpanda tutorial for CDC
Let’s start our tutorial by looking at the Docker Compose file. We encourage you to set up a working directory, and follow along.
mkdir debezium && cd debezium && touch redpanda-debezium.compose.yml
# redpanda-debezium.compose.yml
version: "3.3"
services:
redpanda:
image: vectorized/redpanda
ports:
- "9092:9092"
- "29092:29092"
command:
- redpanda
- start
- --overprovisioned
- --smp
- "1"
- --memory
- "1G"
- --reserve-memory
- "0M"
- --node-id
- "0"
- --kafka-addr
- PLAINTEXT://0.0.0.0:29092,OUTSIDE://0.0.0.0:9092
- --advertise-kafka-addr
- PLAINTEXT://redpanda:29092,OUTSIDE://redpanda:9092
- --check=false
connect:
image: debezium/connect
depends_on:
- redpanda
ports:
- "8083:8083"
environment:
BOOTSTRAP_SERVERS: "redpanda:9092"
GROUP_ID: "1"
CONFIG_STORAGE_TOPIC: "inventory.configs"
OFFSET_STORAGE_TOPIC: "inventory.offset"
STATUS_STORAGE_TOPIC: "inventory.status"
mysql:
image: debezium/example-mysql:1.6
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: debezium
MYSQL_USER: mysqluser
MYSQL_PASSWORD: mysqlpw
These services are in the same network, so they are reachable from each other. Also, their service name resolves to their IP addressses in the network. We can ping Redpanda from Kafka Connect:
$ docker ps --format "table {{.Names}}\t{{.Status}}\t{{.Names}}"
Output:
NAMES STATUS NAMES
debezium_connect_1 Up 6 minutes debezium_connect_1
debezium_mysql_1 Up 6 minutes debezium_mysql_1
debezium_redpanda_1 Up 6 minutes debezium_redpanda_1
$ docker exec -it debezium_connect_1 /bin/bash # starts and attaches to the shell inside container
[kafka@a48a914cf7f1 ~]$ ping redpanda
PING redpanda (192.168.16.3) 56(84) bytes of data.
64 bytes from debezium_redpanda_1.debezium_default (192.168.16.3): icmp_seq=1 ttl=64 time=0.152 ms
64 bytes from debezium_redpanda_1.debezium_default (192.168.16.3): icmp_seq=2 ttl=64 time=0.103 ms
^C
--- redpanda ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1010ms
rtt min/avg/max/mdev = 0.103/0.127/0.152/0.026 ms
The environment variables and values are intended to be self-explanatory, but you can go to the Docker Hub and read about their meaning.
Run docker-compose -f redpanda-debezium.compose.yml up
Once everything has successfully started, open a new terminal session and enter into the Redpanda shell.
$ docker exec -it debezium_redpanda_1 /bin/bash
redpanda@67f3306a7a30:/$ rpk topic list
Name Partitions Replicas
inventory.configs 1 1
inventory.offset 25 1
inventory.status 5 1
These are management topics required for Kafka Connect to run in distributed mode.
Let’s do the same for MySQL:
$ docker exec -it debezium_mysql_1 /bin/bash
root@7119b581859f:/$ mysql -u mysqluser -pmysqlpw
mysql> use inventory; # this is example database pre-created during start-up
mysql> show tables;
+---------------------+
| Tables_in_inventory |
+---------------------+
| addresses |
| customers |
| geom |
| orders |
| products |
| products_on_hand |
+---------------------+
6 rows in set (0.00 sec)
# we are interested in customers
mysql> select * from customers;
+------+------------+-----------+-----------------------+
| id | first_name | last_name | email |
+------+------------+-----------+-----------------------+
| 1001 | Sally | Thomas | sally.thomas@acme.com |
| 1002 | George | Bailey | gbailey@foobar.com |
| 1003 | Edward | Walker | ed@walker.com |
| 1004 | Anne | Kretchmar | annek@noanswer.org |
+------+------------+-----------+-----------------------+
4 rows in set (0.00 sec)
Now we need to start capturing changes. For this purpose, Kafka Connect exposes a REST API through which we can upload configuration parameters. For example:
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"database.history.kafka.bootstrap.servers": "redpanda:9092",
"database.history.kafka.topic": "schema-changes.inventory"
}
}
Some important parameters:
connector.class- class that implements capturing logic. In our case, it will read mysql binlogs.database.server.\*- to identify mysql server. Will be used as a prefix when creating topics.database.include.list- list of table names to include.database.history.kafka.topic- connect will upload db schemas there, and will use it to inform from where connect should begin reading if restarted.
All we have to do is to upload this configuration to Kafka Connect:
Note: perform this curl command on the host machine. The Docker Compose file exposes port 8083.
curl --request POST \
--url http://localhost:8083/connectors \
--header 'Content-Type: application/json' \
--data '{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"database.history.kafka.bootstrap.servers": "redpanda:9092",
"database.history.kafka.topic": "schema-changes.inventory"
}
}'
# response should be 201
After executing the above curl command, Kafka Connect is set up. It will start reading binlogs from MySQL and streaming changes to Redpanda.
redpanda@67f3306a7a30:/$ rpk topic list
Name Partitions Replicas
dbserver1 1 1
dbserver1.inventory.addresses 1 1
dbserver1.inventory.customers 1 1
dbserver1.inventory.geom 1 1
dbserver1.inventory.orders 1 1
dbserver1.inventory.products 1 1
dbserver1.inventory.products_on_hand 1 1
inventory.configs 1 1
inventory.offset 25 1
inventory.status 5 1
schema-changes.inventory 1 1
As you can see, Kafka Connect created topics for each table. We are interested in the dbserver1.inventory.customers topic, as it is the only table present in include.list.
redpanda@67f3306a7a30:/$ rpk topic consume dbserver1.inventory.customers
... # it will start streaming changes as json payload
{
"key": {...}
"message": {...}
"partition": 0,
"offset": 0,
"timestamp": "2021-08-29T16:47:04.436Z"
}
This is the representation of a change to the row in customer table. The message field contains details about schema, operation type, and the before and after value of the row.
{
"schema": {
"type": "struct",
"fields": [ ... ],
"optional": false,
"name": "dbserver1.inventory.customers.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "1.6.1.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 1630246982521,
"snapshot": "true",
"db": "inventory",
"sequence": null,
"table": "customers",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000008",
"pos": 154,
"row": 0,
"thread": null,
"query": null
},
"op": "r",
"ts_ms": 1630246982521,
"transaction": null
}
}
Do not interrupt consumption by trying to make changes to the customers table.
mysql> UPDATE customers SET first_name='Anne Marie' WHERE id=1004;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
As you update, you should see new records arriving in the consumer.
Feel free to have fun and create as many changes as you want!
Here is an overview of what is happening:
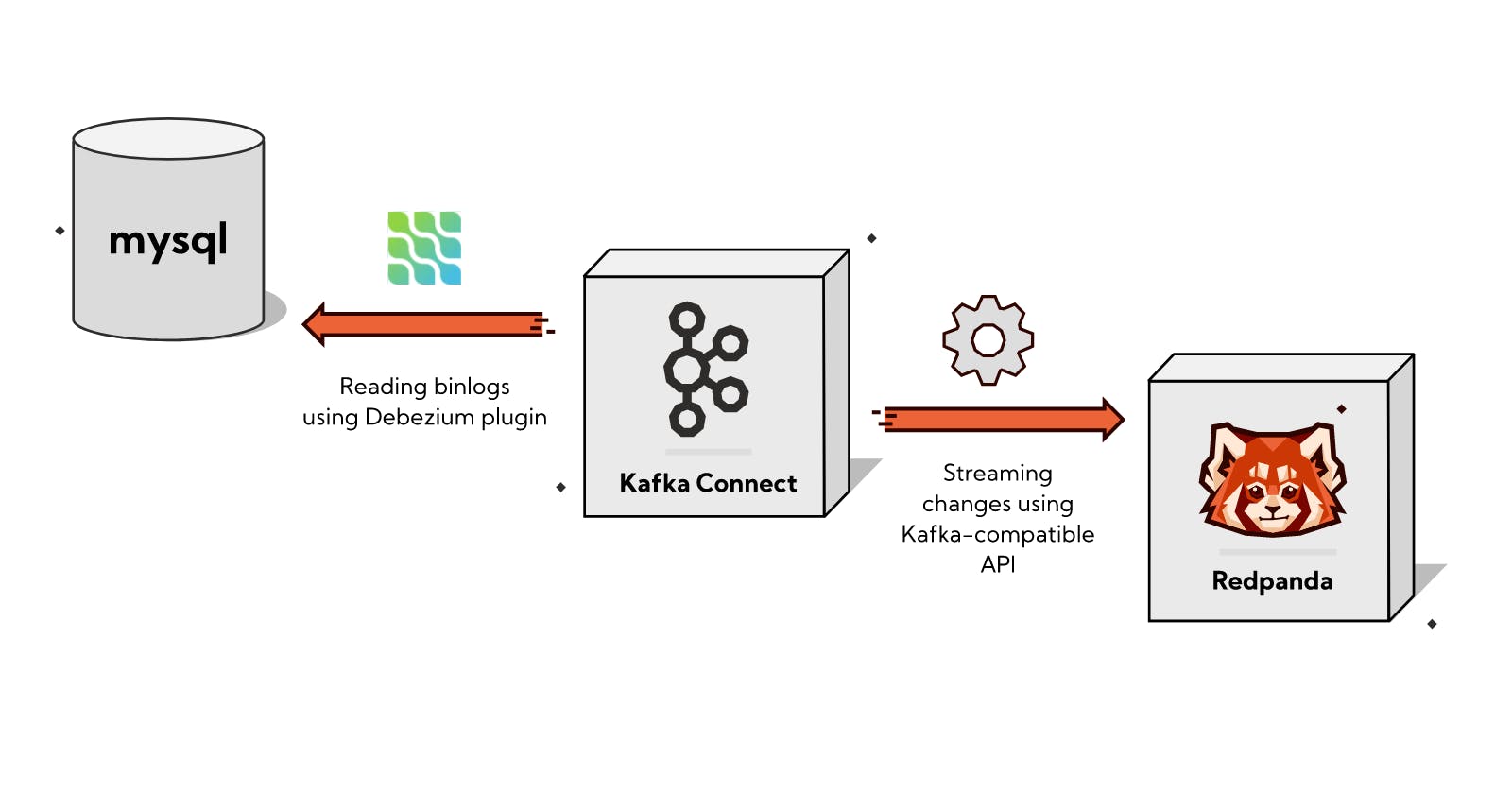
Summary
You can see how easy it is to set up CDC streams using Redpanda. Feel free to play around and set up CDC streams from other popular database systems.
Credits
This tutorial is heavily inspired by the Debezium getting started tutorial. There you can find additional details about configuration parameters and set up with Kafka+ZooKeeper, so feel free to check it out.
And, don't forget to join the Redpanda Community on Slack.